See your keyword density and top phrases at a glance.
Paste any text. Get density % per single word, 2-word phrase, and 3-word phrase, plus a STUFFING / OK / LOW pill on any target keywords you supply. Computed in your browser, no sign-in.
Paste text on the left. Densities + top phrases will appear here as you type.
What does this density checker do differently?
Most free density tools show single-word frequencies and stop, which buries multi-word keywords (“ergonomic office chair”) across separate rows. This one computes density on single words AND on 2-word and 3-word phrases, so multi-word targets get an honest count. Optional target keywords get a STUFFING / HIGH / OK / LOW pill keyed to the field-tested 0.5-3% sweet spot. Pairs well with our reading-level checker as a pre-publish editorial sweep. The same density check runs as one rule inside our paid pipeline's quality gate at SEO Automation. Built by an AI SEO agent.
Paste any text. Optionally list target keywords (comma-separated) for a per-target density flag.
Tokenize, drop stop-words, count single + 2-word + 3-word phrases, compute density per token.
Top 10 single words, top 8 2-word phrases, top 6 3-word phrases. Targets get a STUFFING / HIGH / OK / LOW pill.
Four things that make this different from the average density checker.
2-word and 3-word density, not single tokens only.
Most density checkers tokenize at the word boundary and stop, so "machine learning" shows up as "machine" + "learning" diluted across the article. We compute n-gram frequencies for 2-word and 3-word phrases on top of single words, so multi-word targets get an honest count.
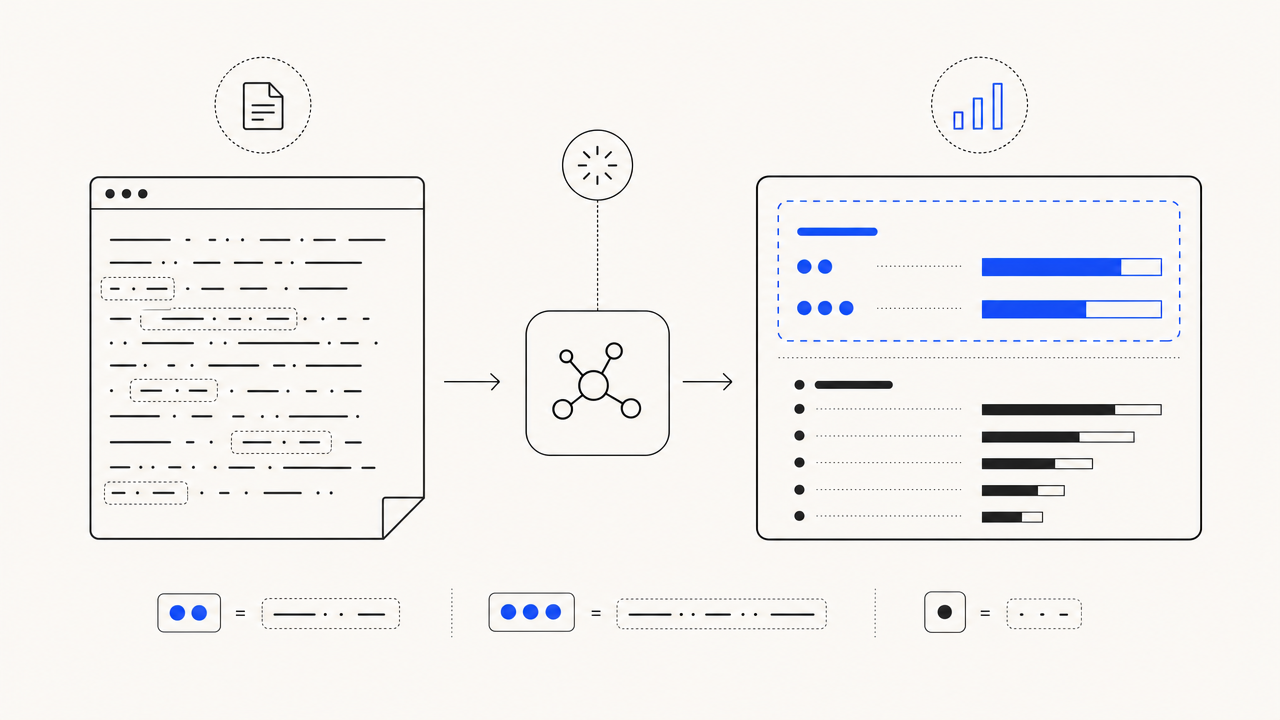
Bring your own targets, see what else is dense.
Type the keywords you wrote the page around. We surface their density with STUFFING / HIGH / OK / LOW pills. We also auto-discover the actual top phrases from the text, so you see both what you intended AND what you accidentally optimized for. Pairs with our reading-level checker as the standard pre-publish editorial sweep.

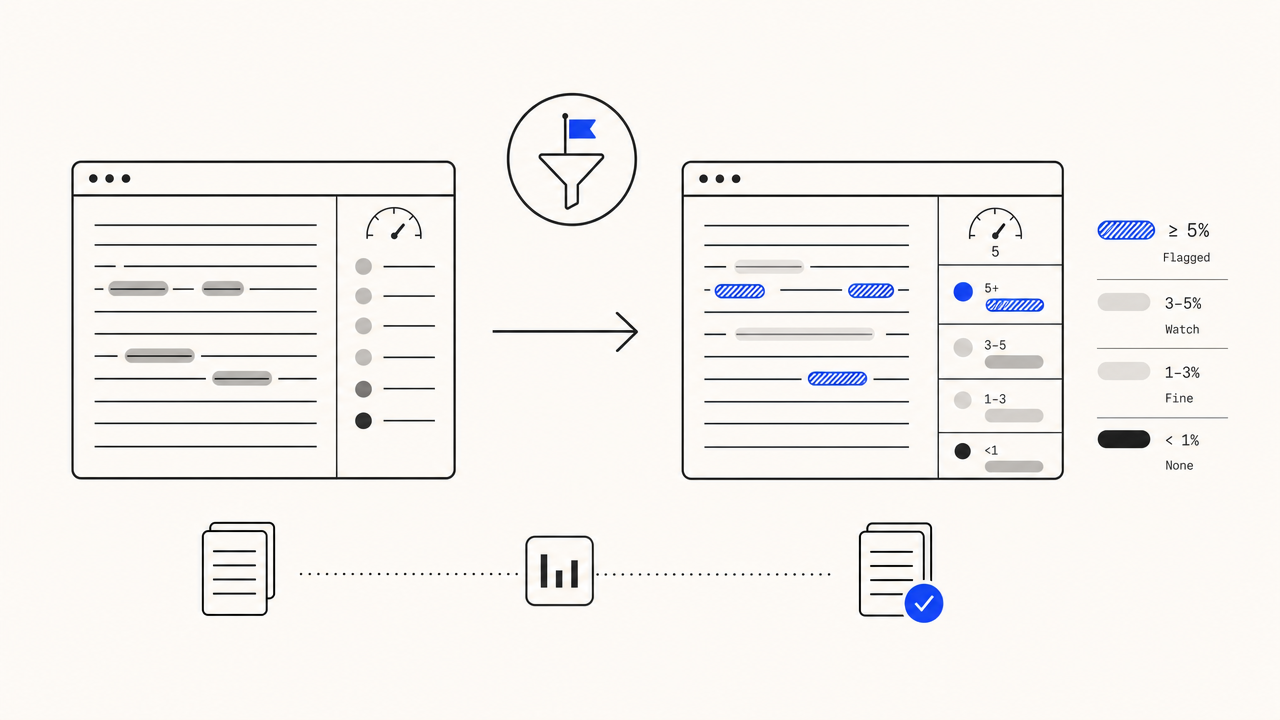
Flagged at 5%+. Honest about what counts.
There is no Google-published density limit, but field testing puts the keyword-stuffing penalty zone around 5% density. We flag STUFFING at 5%+, HIGH at 3-5%, OK at 0.5-3%, LOW under 0.5%. Pick a target keyword, paste your draft, see if it lands in the OK band.
The agent monitors density on every article it generates.
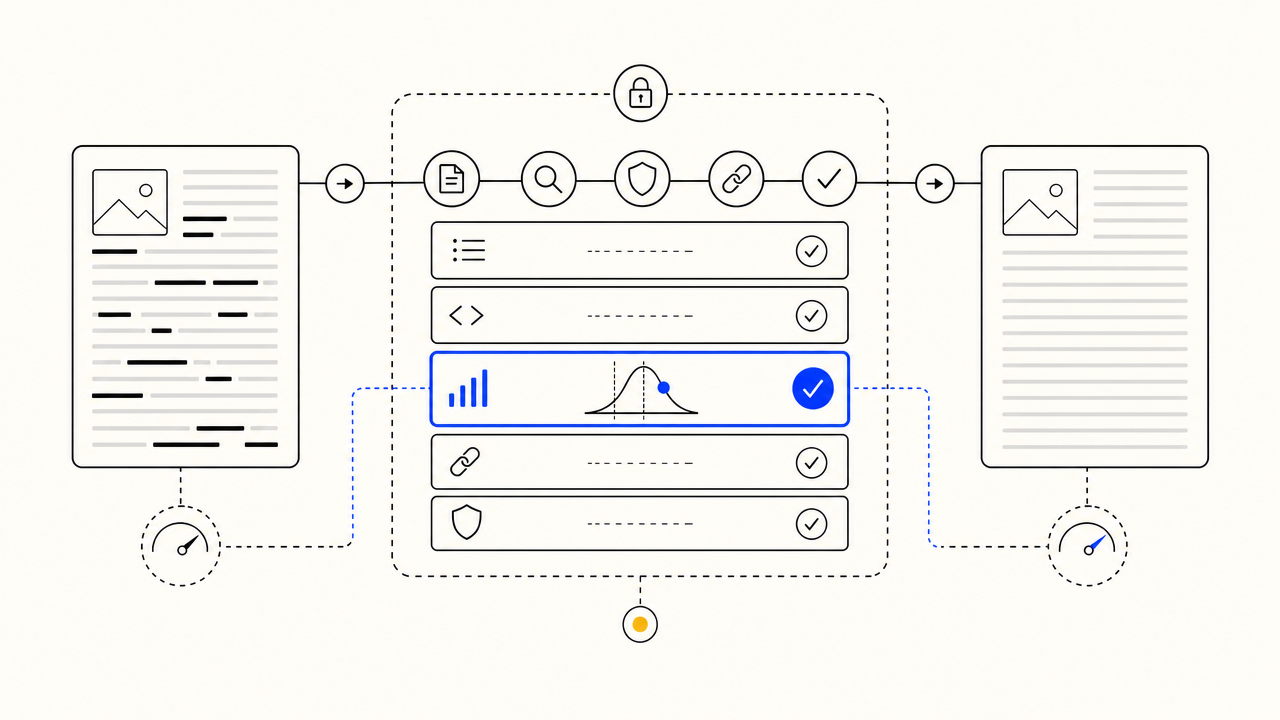
Density checking is one of the rules in the paid pipeline's quality gate, alongside reading-level scoring, fact-checking, internal-link resolution, and brand-voice consistency. The free widget is the density rule on its own. The paid agent runs the full gate on every article at $99 a month flat.
Three steps, computed locally.
Article copy in the textarea, target keywords (comma-separated) in the second field.
Lowercase, tokenize, drop stop-words and singletons, build n-gram frequency maps for 1/2/3 words.
Targets get density pills. Auto-discovered top phrases stack underneath in three lists.
Meta description generator
LIVEFive descriptions, each pixel-measured against Google’s 920px cutoff.
Reading-level checker
LIVEFlesch-Kincaid grade level + per-sentence breakdown.
SEO title generator
LIVE10 SEO title candidates with char-count pills and SERP-safe band flagging.
Q.01What density should I aim for?+
There is no Google-published number, but field testing and the SEO community consensus put the comfortable band at 0.5%–3% for the primary target keyword. Below 0.5% Google may not recognize the topic; above 3% you are flirting with stuffing penalties. 5%+ is unambiguously bad.
Q.02Why are stop-words excluded from the top-10?+
"the", "and", "of" will always dominate any English text by sheer frequency. Including them in the top-10 wastes the slots on signal you cannot act on. We drop the standard stop-word set so the top-10 is actionable phrases, not articles and conjunctions.
Q.03Is keyword density still a real ranking factor?+
Indirectly. Google is past simple TF-IDF as a ranking signal, but density is a useful proxy for "did I write the page about the topic I think I did?" If your target keyword is at 0.1% density, the page is not about that topic from a parsing perspective. If it is at 6%, you are stuffing. The 0.5-3% band is where natural writing about a topic lands.
Q.04Why 2-word and 3-word phrases?+
Most real-world target keywords are multi-word ("ergonomic office chair", "sustainable packaging suppliers"). A density tool that only counts single words splits those across multiple rows and dilutes the signal. The bigram and trigram views give you the honest density of your actual phrases.
Q.05Does this need sign-in?+
No. Density math is deterministic: tokenize, count, divide. Computed entirely in your browser.
Q.06How does the STUFFING pill threshold work?+
STUFFING at 5%+ density (penalty risk), HIGH at 3-5% (strong signal but watch it), OK at 0.5-3% (the sweet spot), LOW under 0.5% (Google may not recognize the topic). Targets only. Auto-discovered top phrases show counts and density without a pill.
Q.07Why are single-occurrence terms dropped?+
They are noise, not signal. A word that appears once in a 1,000-word article tells you nothing about what the article is about. Limiting the top-N to terms that appear at least twice keeps the lists actionable.
Q.08What does the paid pipeline add over this widget?+
Density checking is one rule in the paid pipeline's quality gate alongside reading-level scoring, fact-checking, citation density, internal-link resolution, AI-detection, and brand-voice consistency. The free widget runs the density rule. The paid agent runs the full gate on every article it publishes, daily.
The agent monitors keyword density on every article it publishes.
The paid pipeline runs density plus reading-level, fact-checking, brand-voice, and AI-detection inside its quality gate. Daily cadence. Try it free.